
Keeping up with Google’s privacy changes is not easy. It seems like just when we feel like we’ve perfected the integration to provide the best possible user experience, there is a new behaviour that kills conversions.
The latest one of these is the opt-in only permissions on the OAuth consent screen. Previously people were shown a list of permissions to grant and they could allow all of them, or they could deny all of them. Now Google has taken to displaying some basic permissions with an immutable checkbox and other, extended permissions with an unselected checkbox.
The first potential issue is that some people might not understand that they need to click on each permission that they want your application to have. They might reasonably assume that either your application or Google knows what is best and will provide that as the default for them. Thus they would follow the direct path to the big “Approve” button on the screen and be confident that their expectations will now be fulfilled.
Except that is not how things work anymore, apparently. Google has decided that it is best to make people read the consent form and deliberately include every permission that they want your app to have.
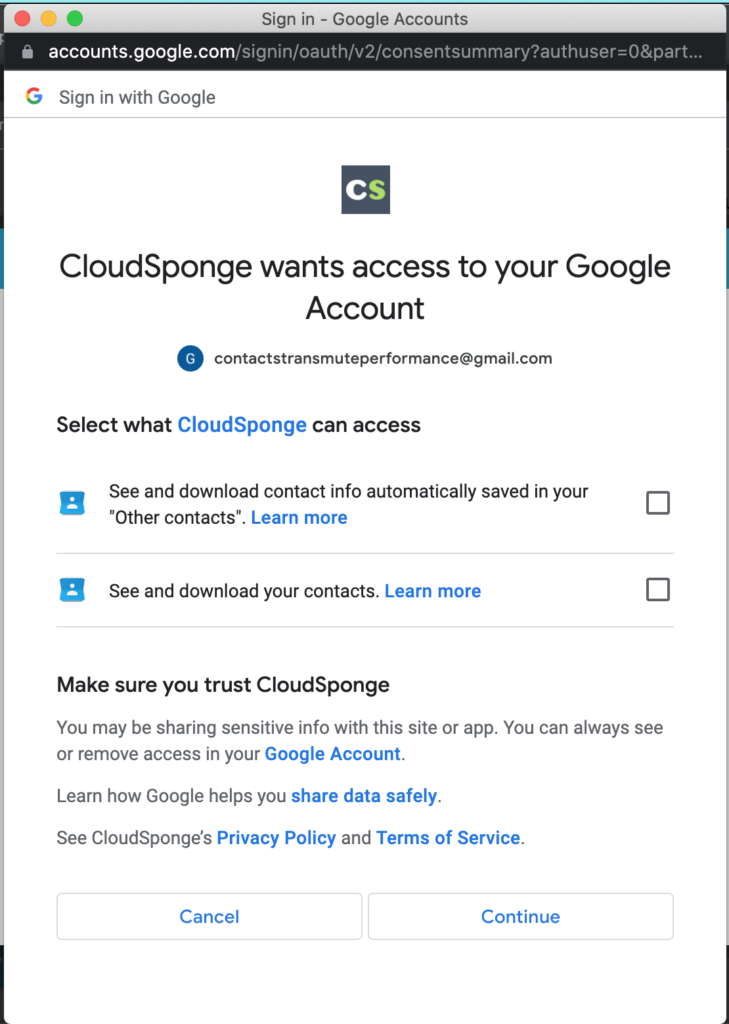
Most internet users don’t think this way. The result is that for us, we’re seeing address books with 0 contacts, because the user didn’t tick off those checkboxes.
So how do we solve this?
Here’s where we begin the dance between it all.
There is an exception to the empty checkbox situation: request single permissions. Google calls this incremental authorization and the changes I referred to are driving us (as designers and developers) towards the way they want us to work. Incidentally, Google is championing this idea as an extension to the OAuth 2.0 framework, so we might see other OAuth providers adopting it.
The idea is this: ask only for the permission that you require at the time when you require it.
For example, your app might do a number of things with Google data:
- Sign in with Google
- Read from your Contacts
- Read your Other Contacts
Following the incremental OAuth approach, each of these actions requests a separate OAuth permission from the user. Each would:
- Open the popup window,
- Direct the user to sign in to Google or choose their account,
- Review and approve the single permission,
- Do the OAuth token exchange, and
- Finally access the appropriate Google APIs to do the work.
In the old way, apps might have presented a long list of permissions to users. Some of these permissions might not have been used in all cases. So the incremental authorization aligns with the good security principle of least access. I can understand the rationale behind the decision.
I don’t have to like it though.
The reason I don’t like it has to do with how granular the OAuth permissions are. Our CloudSponge Contact Picker is attempting to meet users’ expectations of searching their Google Contacts. The most common experience of this is when you compose an email in Gmail. As you start typing, all the contacts you’ve had an email conversation with are filtered and suggested.
This has trained people to think of their Google Contacts as having been automatically created. It’s frequently the case that people have very few contacts in their “My Contacts”. Most are listed in the “Other Contacts” which is a list that is automatically created by Google when you reply to an email.
To create this experience in the Contact Picker, we need to request access to both sources of contacts. Since the user’s intention is singular but the scopes are multiple. It’s not really fair of Google to treat it this way.
That’s why we came up with the following solution.
UX Redesign
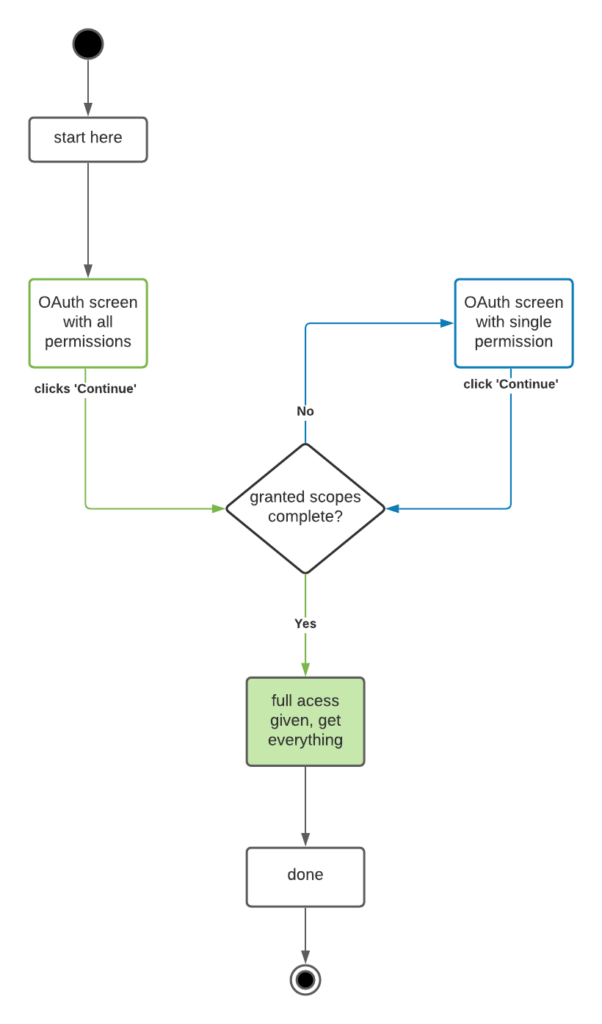
The solution that we came up with is to straddle both possibilities. We will assume the best, and prepare for the worst.
Assume the best from users and display to them all the permissions, the first time round. People who are paying close attention will notice the disconnect between what they had intended and when the permission page shows. These clever people will tick the extra checkboxes. We’ll be able to complete the access to their contacts and populate the Contact Picker with all the people they expected to see.
However, this won’t happen all the time. It won’t even happen most of the time. Our metrics show us that only about 33.5% are paying this close attention.
Google’s user experience is confusing two of every three visitors. Bad Google, bad!
So we need to prepare for the worst. When the OAuth flow returns incomplete, we send them back and this time request a single permission at a time.
This means that in the worst case, people see the OAuth consent request 3 times! Not ideal. But it could be worse. And it turns out there are some optimizations that we can make.
Optimization 1: don’t make them pick their google account. The first time they go through the OAuth, recall that they see the basic scopes. Anyone who approves the first step has granted us permission to read their email address.
We can pass the email address as a parameter to subsequent OAuth flows, and Google will skip the login selection page.
- Exchange the code we got to get an
id_tokenfrom Google and pull out the user’s email address. - Include the email as the value of
login_hintin the next pass through the OAuth flow.
NB: According to Google’s docs the email address or Google account id can be used in the login_hint. My experience is that the account it (the sub or subject value from the JWT) will still display the account chooser but with only the login selected. Better but not great.
Optimization 2: don’t manage separate access tokens
Three times through the OAuth flow means three codes, three calls to exchange and three different access tokens, right? Yes. But each subsequent access token can include the scopes from the previous ones if you know what you are doing. Include include_granted_scopes=true in your query to the OAuth flow and you’ll level up each access token so that you only need to deal with the most recent one.
Here what the UX looks like:
Architecture
For us, the way forward was clear. However, we need to work with our existing architecture and current requirements to support other OAuth flows for Microsoft and Yahoo. Like the open heart surgeon, this was a delicate operation on the core functionality/beating heart of our business.
All this is to lay the background for why we made a significant change to our Contact Picker. Previously, the Contact Picker was able to rely on having all the required permissions, or none of them, when the OAuth flow completed. The incremental auth changes introduces all kinds of grey. Our app might be able to get an access token, but which API can we use it on?
These changes affect the architecture because we used to be able to treat the OAuth flow as all or none. Either the result was successful and we got all the permission was requested. Or the result was an error and there was nothing we could do with it.
Because of the all or none permissions, when we designed our API we left all upstream access and processing to a background thread. This lets us have predictably fast responses from our server to prevent delayed updates in the UI.
We are now faced with partial success or false success where the result is successful, but it’s not enough for us to do our job. Thanks a lot, Google. That was sarcasm.
Temporal storage to the rescue
The result is that I was finally able to justify a move towards the architectural change I’ve been planning for a long time. Break the dependency between our database and our real time API. We capture every access of our API in our database (nothing personal, that would be bad). This gives us a wealth of data to report on and is the foundation of our Better Sharing Metrics. But it means our database gets huge over time (and we’ve been at this for over a decade). Managing tables this big is tedious and problematic. Despite all the advantages of using AWS Aurora for managed databases, there are still operations that cause database to be offline or table locks that cause connections to timeout. The solution in my mind is to use a fast in-memory store for all of our API management. This has several advantages:
- Fast: random access memory means we can look up data quickly and response quickly on our API.
- Temporary: any personal data/credentials that are exposed to our system are automatically deleted. This one is super important for me because I don’t sleep at night unless I know that any exposure is limited to the 5 minutes that we keep any sensitive information in our system.
- Robust: go ahead and run that long database migration. Data will queue until the database is ready to be written to. Did someone run DROP * on the database and we need to restore from backup? That sucks, but our API stays up.
There are few drawbacks:
- Engineering effort and QA
- Risk of coding errors: bugs happen to the best of us. When you maintain software for long enough you hesitate to change things.
- It aint broke: our current system is working. Related to the previous drawback but worth calling out so we have symmetry with the list of benefits.
OK, I’ve decided it is time but we don’t need to lose sight of the main goal here. Provide state information to our API so the app can re-authorize users as needed.
Other Considerations
There is an interesting new use case to consider. What happens when the user cancels one of the scopes as they are presented the UI? (I’ve highlighted this situation in my state-diagram). Our OAuth redirect URI will receive an error. In the past, any error here meant the flow failed so it is time to stop. Now that we are using incremental authorization, it’s possible that the error came after the user gave us some permissions, so we’re not dead in the water here.
Since we’ve kept the most recent access_token, we can still use it to proceed with as much data access as we’ve been given.
Alternatively, we could ask them again. But I don’t think this is a very good call.
Implementations
I won’t get into too much detail. You’ve been patient to humour me so far.
We still rely on the database. But I’ve removed some of the dependencies with this change. When an authorized access is granted, all the data required to obtain OAuth consent is put into a memory store and the authId is passed in the OAuth URL. When the request returns with partial success, our app redirects the popup window back to the OAuth flow with a single additional scope. When the request returns with all the scopes granted, our app passes the access_token to the background thread for collecting the contacts from the upstream. Because the code was already used to get the token, we cannot re-exchange it, so the background thread needs to know not to do that again.
Moving forwards, we’ll continue to delete the dependencies on the database from our API. The events API currently uses the database but caches the results. These events do not need to be captured in the database until the API call is finished and the data can be put into a queue for long term storage.
The contacts API already uses memory, not database to hold the data.
I don’t believe that Google is trying to punish us, but they are encouraging us towards different habits.
Are these habits better? Does it really matter? You are not going to fight Google.


